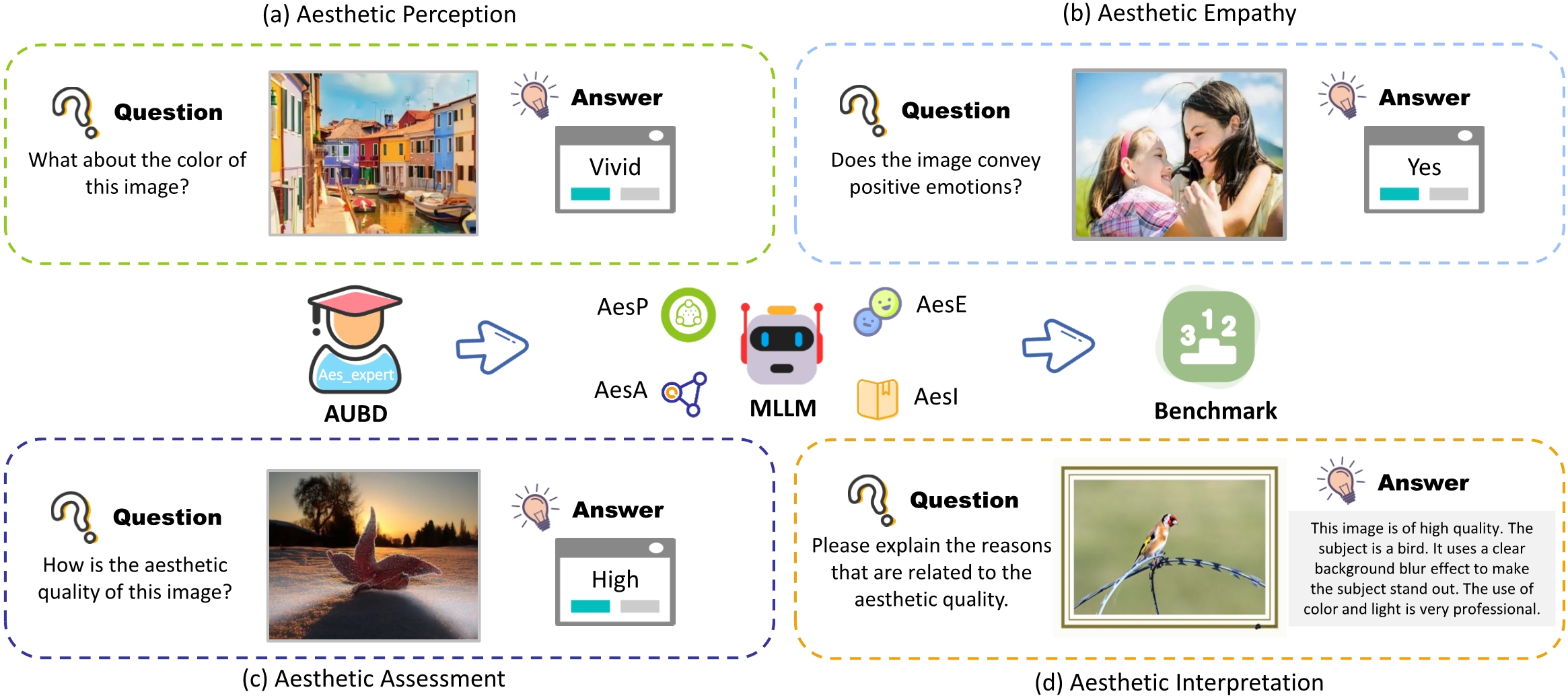
AesBench is an expert benchmark to comprehensively evaluate the aesthetic understanding abilities of MLLMs, which features High-Quality Data and Integrative Criteria.
High-Quality Data: The expert-labeled Aesthetic Understanding Benchmark Dataset (AUBD) consists of 2,800 diverse sourced images covering natural images, artistic images, and artificial intelligence-generated images.
These images are annotated by subjects with professional backgrounds in aesthetics, which comprises researchers engaged in aesthetics computing, educators versed in aesthetic theory, and art students with proficient art skills.
Integrative Criteria: A set of integrative criteria is proposed to systematically evaluate MLLM across four shallow-to-deep dimensions: Aesthetic Perception, Aesthetic Empathy, Aesthetic Assessment, and Aesthetic Interpretation.
(Results with yellow background are closed-source commercial models; the others are open-source models.)
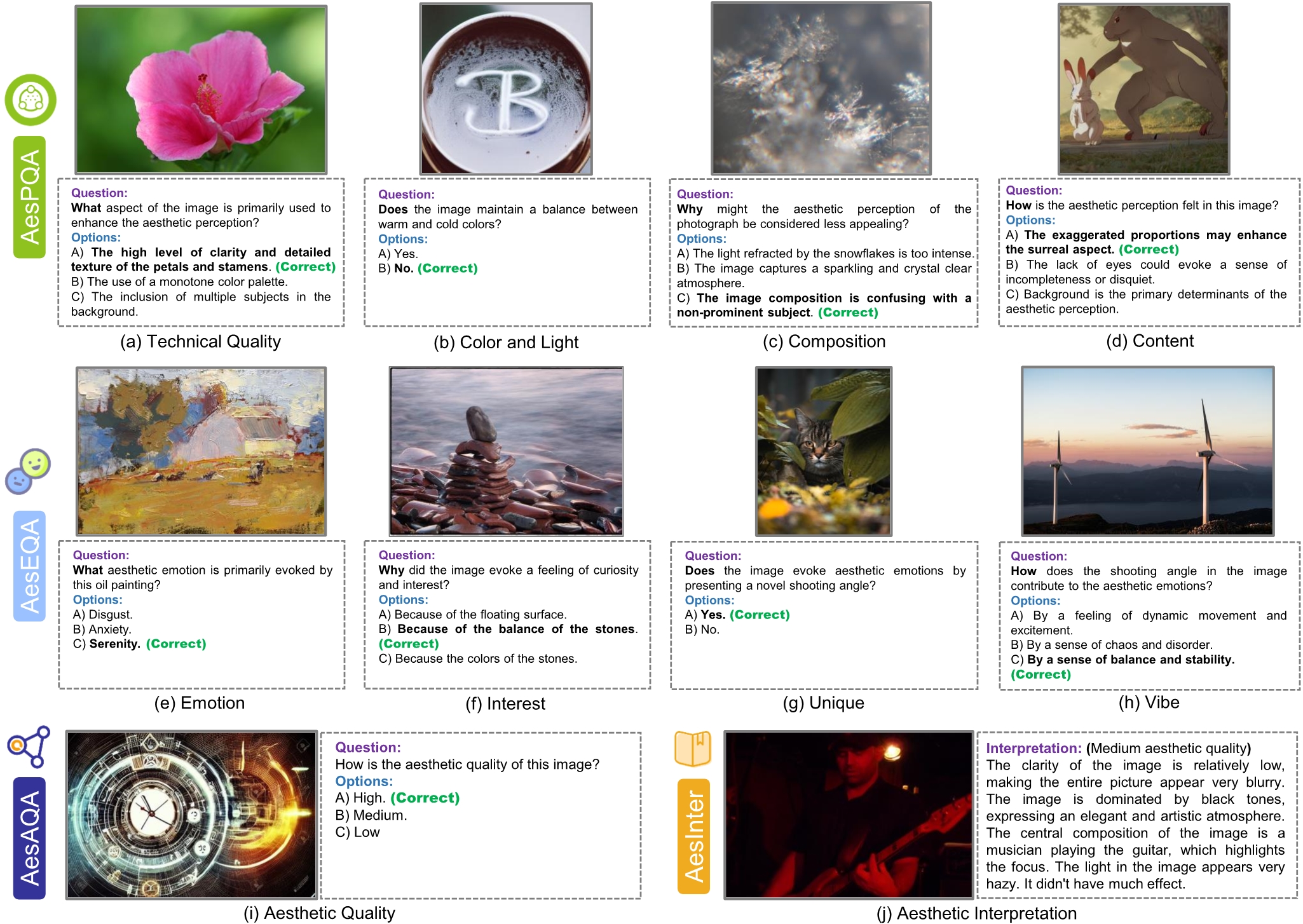
Evaluation results on the Aesthetic Perception ability.
Evaluation results on the Aesthetic Empathy ability.
Evaluation results on the Aesthetic Assessment ability.
Evaluation results on the Aesthetic Interpretation ability.

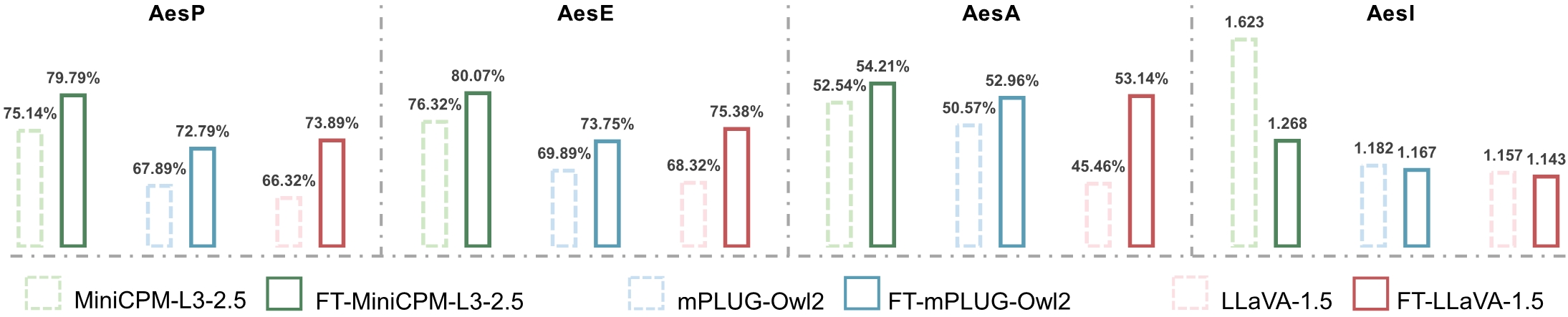
To further explore the aesthetic understanding potential of current open-source MLLMs, we attempt to exploit existing aesthetic data to optimize the top-performance counterparts with different architectures as fine-tuned models. There are two minor findings:
(1) Aesthetic instruction fine-tuning significantly improves the question-answering accuracy of MLLMs on perception, empathy and assessment.
(2) Simple instruction fine-tuning may not achieve better interpretation ability.
These findings inspire us to consider two potential explorations for future research: developing more effective methods to integrate existing data, and collecting more corpus of human feedback on aesthetic interpretation.
@article{AesBench,
title={AesBench: An Expert Benchmark for Multimodal Large Language Models on Image Aesthetics Perception},
author={Yipo Huang and Quan Yuan and Xiangfei Sheng and Zhichao Yang and Haoning Wu and Pengfei Chen and Yuzhe Yang and Leida Li and Weisi Lin},
journal={arXiv:2401.08276},
year={2024}
}